![]()
Towards monitoring in Run 4 and beyond: LHC experiments exchange perspectives on data quality at the HL-LHC

In March of 2026, experts from ALICE, ATLAS, CMS and LHCb gathered at CERN for a dedicated workshop on Data Quality Monitoring (DQM), bringing together developers, coordinators and detector specialists to discuss how the LHC experiments monitor the quality of the data used for physics analyses and how these systems must evolve for the High-Luminosity LHC (HL-LHC) era.
Although each experiment has developed its own monitoring infrastructure over decades of operation, the core challenges ahead are shared. As detector complexity, data volumes, and operational demands continue to grow, all experiments face similar questions: how can data quality be assessed more quickly, more reliably, and with less manual effort, while still retaining the expert oversight required for precision physics?
Data quality monitoring sits at the intersection of detector operations, computing, and physics analysis. During data-taking, thousands of quantities, ranging from electronics status to high-level physics observables, are continuously monitored to detect detector malfunctions, calibration issues, reconstruction problems, and other anomalies that could compromise the quality of the recorded data. The information collected by DQM systems ultimately feeds into the data certification process, which determines which portions of the data are suitable for physics analyses.
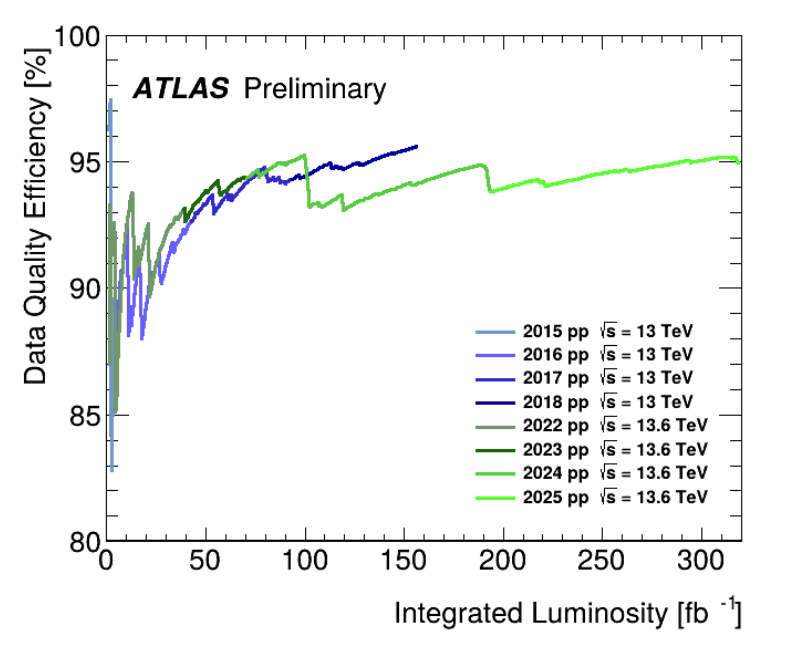
Figure 1: Fraction of data collected by the ATLAS experiment certified as physics-grade quality in Runs 1 to 3.
One recurring topic was granularity. Historically, data certification decisions have often been made at the level of entire runs. However, several experiments have reported growing interest in identifying and isolating short-lived problems that affect only small fractions of a run. CMS presented its recent experience with high-granularity monitoring, in which data quality can be assessed on timescales of roughly 20 seconds, enabling the identification of subtle detector effects that would otherwise remain hidden in run-averaged quantities. Similar discussions are taking place in other experiments as they consider how to increase the precision of their certification workflows.
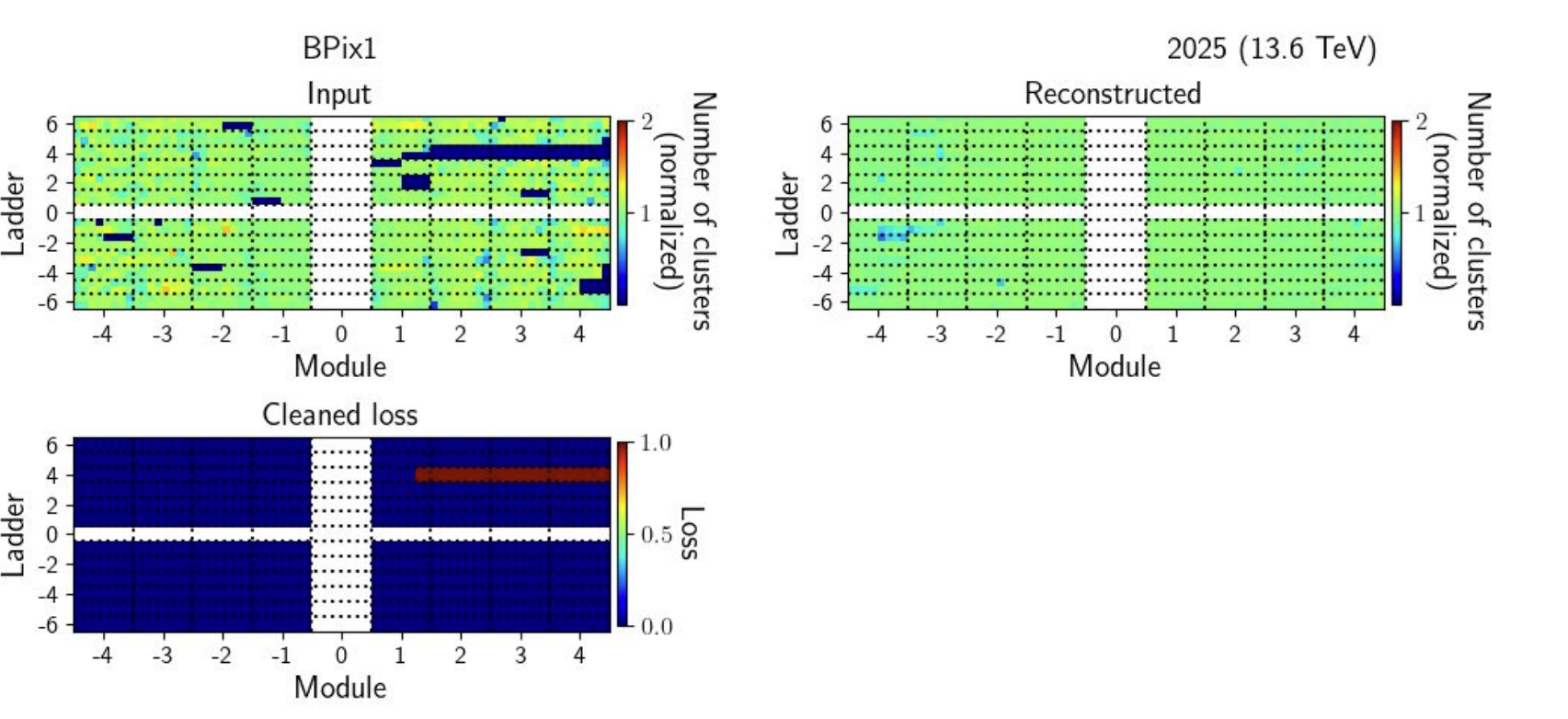
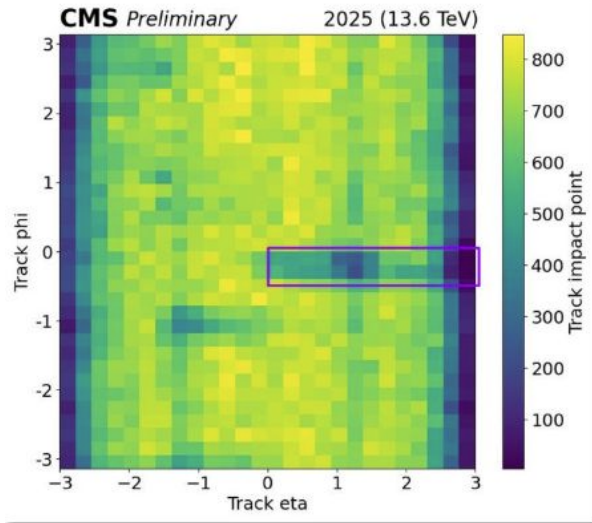
Figure 2: Example of the final stages of the CMS pixel-tracker anomaly-detection workflow, showing the preprocessed input, its reconstruction, and the cleaned loss map used to identify anomalous readout regions. The cleaned loss map highlights the candidate anomaly after thresholding and filtering. A temporary malfunction in the electronics of the CMS pixel tracker results in fewer tracks than normal being reconstructed in the corresponding portion of the detector (top). With the high-granularity pipeline deployed in Run 3, these instances are automatically identified (bottom).
Another major theme was the accessibility of monitoring data. Modern DQM systems generate vast amounts of information, but the workshop highlighted that making this information available in a flexible, machine-readable form is becoming just as important as collecting it. Several experiments already provide examples of this approach: ATLAS discussed web-based monitoring and data access tools that enable users to query and correlate detector performance metrics across multiple systems; similar efforts are also underway in ALICE and LHCb, where monitoring information is increasingly exposed through modern web services and dashboards. Such developments are increasingly viewed as essential infrastructure for future monitoring applications, particularly as experiments explore machine-learning-based monitoring and more automated certification workflows.
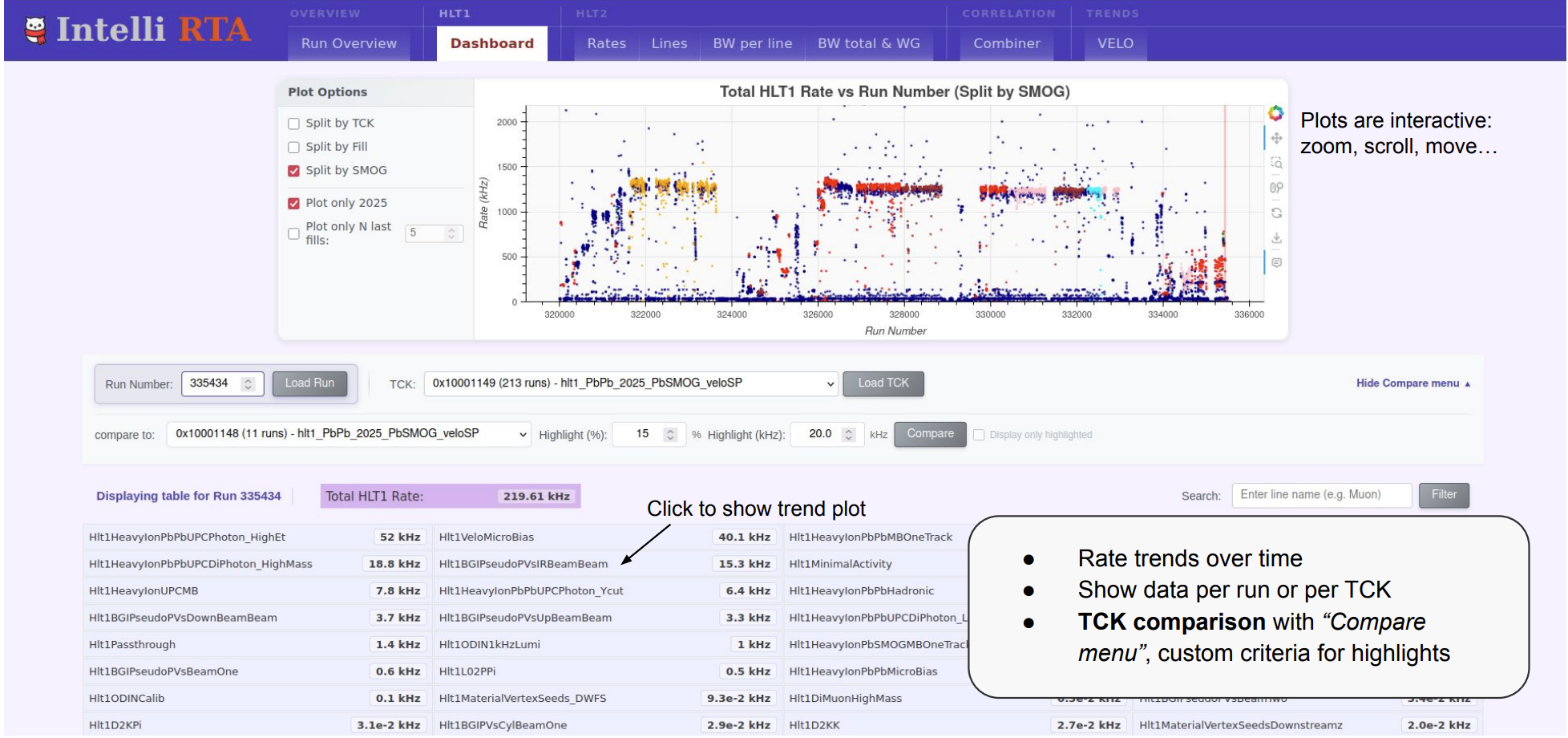
Figure 3: The LHCb monitoring dashboards allow experts to explore correlations between monitoring quantities to assess data quality.
The role of automation was also discussed extensively. Over the past decade, monitoring systems have accumulated numerous specialised tools, scripts and workflows. While these systems have served the experiments remarkably well, maintaining them requires significant effort from detector experts, shifters, and computing teams. Many presentations focused on simplifying operational procedures, reducing duplication, and consolidating functionality into more coherent frameworks. Across the experiments, there was broad agreement that future systems should minimise repetitive manual tasks while preserving transparency and expert control.
Artificial intelligence and machine learning naturally featured prominently in these discussions. Several collaborations presented ongoing efforts to deploy anomaly-detection algorithms capable of automatically identifying unusual detector behaviour. Examples ranged from image-based approaches for detector occupancy maps to statistical and machine-learning models designed to flag unexpected changes in monitoring distributions. At the same time, participants emphasised that identifying an anomaly is only part of the challenge. Determining whether an observed deviation corresponds to a genuine detector problem, an expected change in operating conditions, or simply a benign fluctuation remains a task that requires substantial domain expertise.
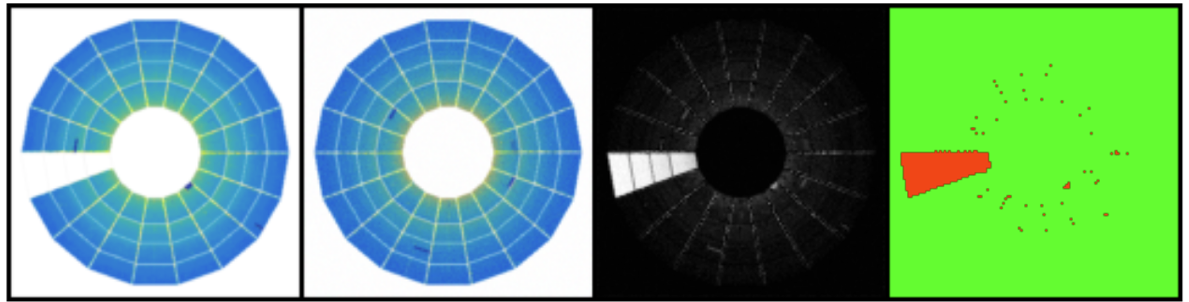
Figure 4: An autoencoder finds anomalies in the ALICE TPC occupancy maps.
The workshop demonstrated that data quality monitoring is no longer simply a detector operations activity. As the LHC prepares for its next phase, it is increasingly becoming a multidisciplinary challenge that combines detector expertise, software engineering, large-scale data management and modern machine-learning techniques. Continued exchanges between experiments will play an important role in ensuring that the enormous HL-LHC data set can be monitored, certified and ultimately exploited to its fullest scientific potential.